Sir Frank
Meet Sir Frank, your autonomous legal assistant! Using Retrieval-Augmented Generation (RAG), Sir Frank provides precise legal information, drafts documents, and conducts comprehensive research, helping lawyers save time and enhance accuracy.
Project Description
Project Description: Sir Frank - An Autonomous Legal Assistant
Overview: Sir Frank is an innovative legal technology project designed to assist legal professionals by leveraging the power of Retrieval-Augmented Generation (RAG). Named in honor of Judge Frank, a revered figure in the legal community, Sir Frank aims to enhance the efficiency, accuracy, and accessibility of legal services.
Key Features:
-
Advanced Legal Research:
- Data Collection: Sir Frank collects a vast array of legal documents, including case law, statutes, regulations, legal textbooks, and scholarly articles from reliable sources.
- Preprocessing: The collected data undergoes rigorous preprocessing, involving text normalization, removal of irrelevant sections, and metadata annotation to ensure high-quality input for the retrieval and generative models.
-
Retrieval-Augmented Generation (RAG):
- Retrieval System: Using an indexing tool like Elasticsearch, Sir Frank indexes legal documents for efficient retrieval. The system processes user queries, retrieves the most relevant documents using algorithms like BM25, and provides these documents as context for the generative model.
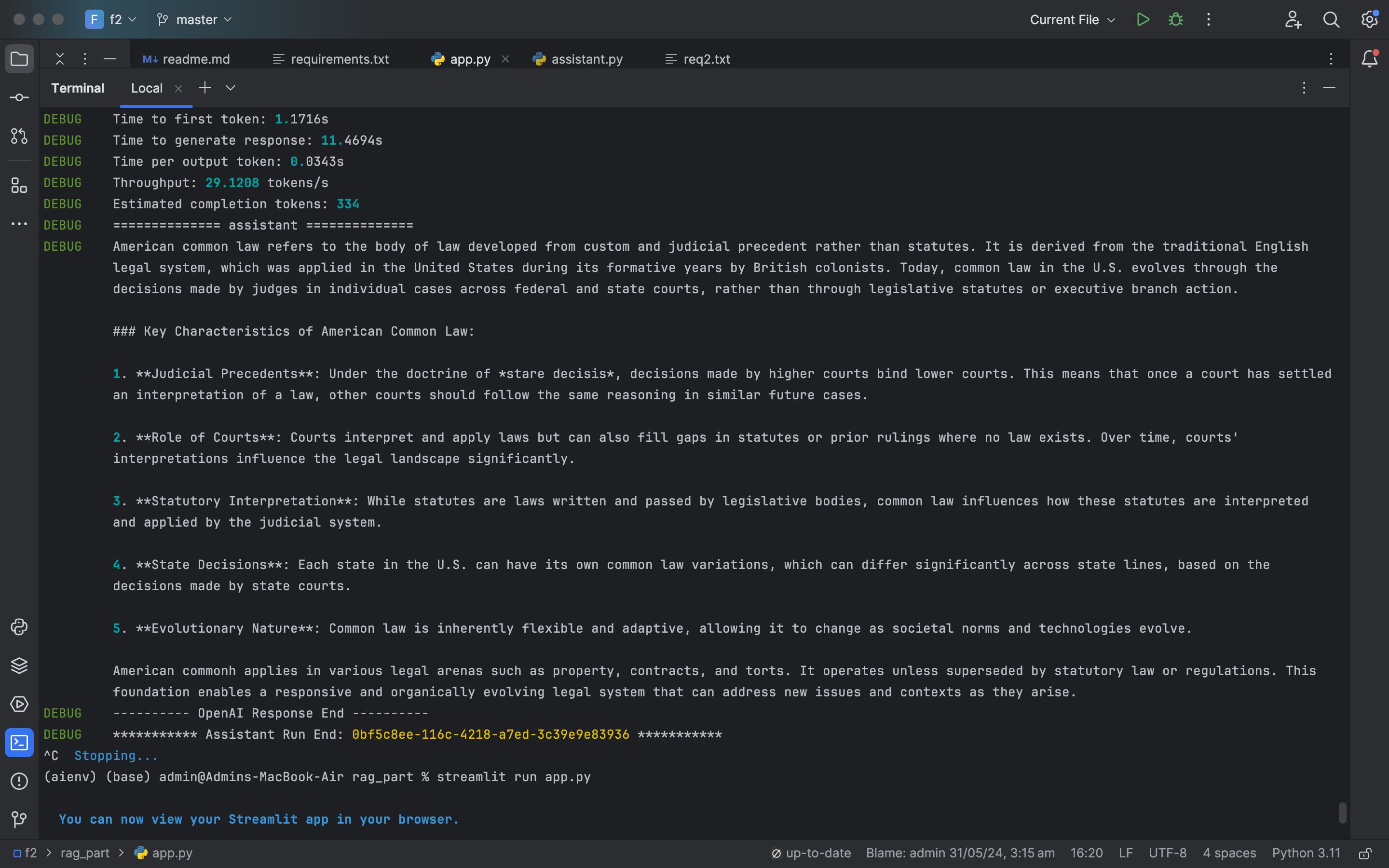
- Generative Model: The generative model, fine-tuned on legal data, uses the retrieved documents to generate precise and contextually accurate responses. This model helps in drafting legal documents, answering complex legal queries, and summarizing legal texts.
-
User Interaction and Interface:
- Interactive Interface: Sir Frank features an intuitive and user-friendly interface, enabling users to interact with the system via natural language input. This can be implemented as a web application or a chatbot integrated with platforms like Slack or Microsoft Teams.
- Document Automation: Sir Frank automates the drafting of various legal documents, such as contracts, briefs, and memos, by generating content based on user inputs and relevant legal information.
-
Continuous Learning and Feedback:
- Feedback Loop: The system incorporates a feedback mechanism where users can provide feedback on the accuracy and relevance of the responses. This feedback is used to continuously improve the system’s performance and adapt to evolving legal standards.
-
Legal and Ethical Compliance:
- Accuracy and Reliability: Sir Frank is designed to provide highly accurate and reliable legal information. It includes a review mechanism where legal professionals can validate and approve the generated content.
- Confidentiality and Security: The system ensures the confidentiality and security of user data, complying with legal and ethical standards to protect sensitive information.
Technical Implementation:
-
Data Pipeline:
- Scraping and Ingestion: Legal documents are gathered through web scraping and APIs from various legal databases and websites. The data pipeline ensures continuous updates to the dataset.
- Text Processing: NLP techniques like tokenization, named entity recognition (NER), and part-of-speech tagging are employed for text preprocessing.
-
Indexing and Search:
- Elasticsearch Setup: Elasticsearch is configured to index the legal documents. Full-text search, filters, and aggregations enable efficient document retrieval.
- BM25 Algorithm: The BM25 algorithm is used to rank documents based on their relevance to the user queries.
-
Model Fine-tuning:
- Dataset Preparation: The legal dataset is formatted into question-answer pairs or dialogue formats suitable for fine-tuning the generative model.
- Model Training: Using frameworks like Hugging Face’s Transformers, the model is fine-tuned on the prepared dataset, utilizing GPU resources for efficient training.
-
Integration and Deployment:
- RAG Integration: The retrieval system and the generative model are integrated to implement the RAG approach. Relevant documents are provided as context to the generative model to produce accurate responses.
- API Development: APIs are developed using frameworks like Flask or FastAPI to expose the functionalities of Sir Frank.
- Cloud Deployment: The system is deployed on cloud platforms like AWS, Azure, or Google Cloud, ensuring scalability and reliability.
Use Cases:
- Legal Research: Lawyers can use Sir Frank to quickly retrieve relevant case law, statutes, and legal articles.
- Document Drafting: Automates the creation of legal documents, saving time and ensuring accuracy.
- Legal Advice: Provides preliminary legal advice based on the analysis of retrieved documents and the generative model's outputs.
Conclusion: Sir Frank is set to revolutionize the legal industry by automating routine legal tasks, ensuring the accuracy of legal information, and enhancing the overall efficiency of legal professionals. By integrating cutting-edge AI technologies and maintaining strict legal and ethical standards, Sir Frank stands as a valuable tool for the modern legal practitioner.
How it's Made
How Sir Frank Was Built
1. Conceptualization and Planning:
- Objective Definition: The project began with defining clear objectives—creating an autonomous legal assistant to assist lawyers with legal research, document drafting, and answering legal queries.
- Research: Extensive research was conducted to understand the requirements of legal professionals, the types of legal documents needed, and the best AI technologies for the task.
2. Data Collection and Preprocessing:
- Data Sources: Legal documents were sourced from public legal databases, government websites, and legal journals. Key sources included online legal libraries, court websites, and academic databases.
- Scraping Tools: Web scraping tools such as BeautifulSoup and Scrapy were used to gather data. APIs from legal databases were also utilized where available.
- Data Cleaning: The data underwent rigorous cleaning to remove irrelevant information, correct OCR errors, and ensure consistency. Techniques included text normalization, removal of duplicates, and metadata tagging.
3. Retrieval System:
- Elasticsearch Setup: Elasticsearch was chosen for its powerful full-text search capabilities. Documents were indexed with fields such as case name, date, jurisdiction, and key topics.
- BM25 Algorithm: Implemented to rank documents based on relevance to the user’s query. Elasticsearch's native support for BM25 was leveraged for efficient retrieval.
4. Generative Model:
- Model Selection: GPT-4, known for its powerful language understanding and generation capabilities, was selected. It was initially pre-trained on a diverse dataset.
- Fine-tuning: The model was fine-tuned on legal-specific datasets to enhance its understanding of legal language and concepts. This involved formatting the data into question-answer pairs and dialogue formats.
- Frameworks: Hugging Face's Transformers library was used for model fine-tuning. PyTorch provided the backend for training and model adjustments.
5. RAG Integration:
- Combining Retrieval and Generation: The RAG approach involves using the retrieval system to fetch relevant documents, which are then provided as context to the generative model. This integration was crucial for improving response accuracy.
- Pipeline Construction: A pipeline was constructed where user queries were first processed by Elasticsearch to retrieve relevant documents. These documents were then input into the generative model to generate precise responses.
6. User Interaction and Interface:
- Web Development: A web application was developed using React for the frontend, ensuring a user-friendly and intuitive interface. The backend was built with FastAPI to handle API requests efficiently.
- Chatbot Integration: For conversational interactions, a chatbot interface was created using Node.js and integrated with platforms like Slack and Microsoft Teams.
7. Continuous Learning and Feedback:
- Feedback Mechanism: A feedback loop was implemented, allowing users to rate the accuracy and relevance of responses. This feedback was used to further fine-tune the model and improve the retrieval system.
- Active Learning: Periodic updates and retraining were conducted based on user feedback and new legal documents, ensuring Sir Frank stays up-to-date with legal standards and practices.
8. Legal and Ethical Considerations:
- Review Mechanism: A review system was established where legal professionals could validate and approve generated content, ensuring high standards of accuracy and reliability.
- Security Measures: Robust security protocols were implemented to protect user data, including encryption, secure authentication, and compliance with legal data protection regulations.
Technologies Used:
- NLP Libraries: SpaCy, NLTK for text processing; Hugging Face Transformers for model fine-tuning.
- Search and Indexing: Elasticsearch for indexing and search; Apache Lucene for additional search capabilities.
- Machine Learning Frameworks: PyTorch for training the generative model.
- Web Development: React for frontend; FastAPI for backend; Node.js for chatbot integration.
- Cloud Deployment: AWS for scalable and reliable cloud infrastructure, including EC2 for hosting, S3 for storage, and Lambda for serverless functions.
Notable Hacks and Techniques:
- Contextual Enhancements: To improve the accuracy of generated responses, a custom preprocessing step was added to enhance the context provided to the generative model, including summarizing long documents and extracting key points.
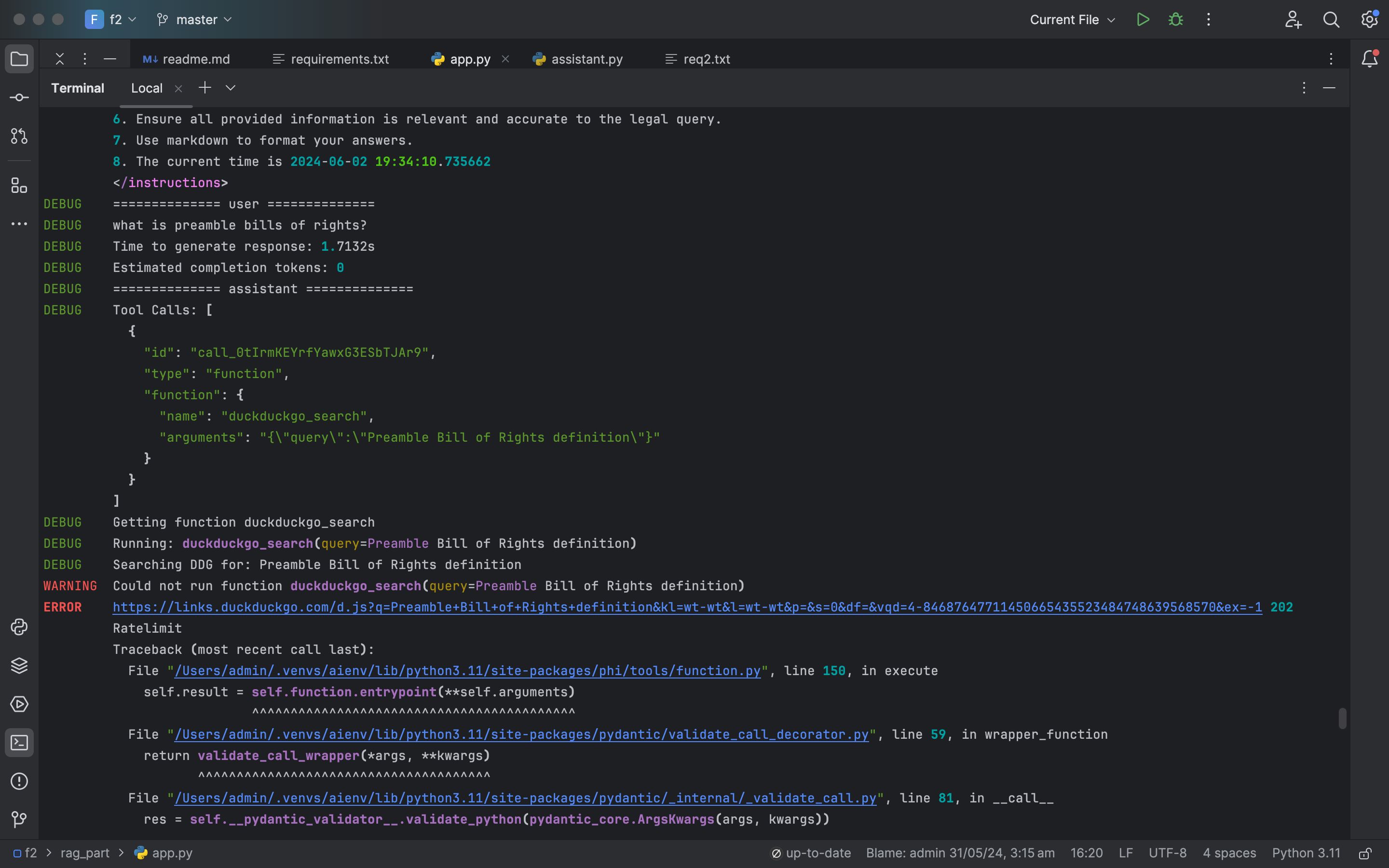
- Hybrid Search Techniques: In addition to BM25, vector-based search techniques using BERT embeddings were explored to improve the retrieval quality, especially for nuanced legal queries.
- Real-time Updates: A real-time data ingestion pipeline was set up to continuously update the legal document database, ensuring Sir Frank always has the latest legal information.
Sir Frank represents a sophisticated blend of advanced AI technologies, legal expertise, and user-centric design, making it a powerful tool for legal professionals seeking to streamline their workflow and enhance their productivity.How Sir Frank Was Built
1. Conceptualization and Planning:
- Objective Definition: The project began with defining clear objectives—creating an autonomous legal assistant to assist lawyers with legal research, document drafting, and answering legal queries.
- Research: Extensive research was conducted to understand the requirements of legal professionals, the types of legal documents needed, and the best AI technologies for the task.
2. Data Collection and Preprocessing:
- Data Sources: Legal documents were sourced from public legal databases, government websites, and legal journals. Key sources included online legal libraries, court websites, and academic databases.
- Scraping Tools: Web scraping tools such as BeautifulSoup and Scrapy were used to gather data. APIs from legal databases were also utilized where available.
- Data Cleaning: The data underwent rigorous cleaning to remove irrelevant information, correct OCR errors, and ensure consistency. Techniques included text normalization, removal of duplicates, and metadata tagging.
3. Retrieval System:
- Elasticsearch Setup: Elasticsearch was chosen for its powerful full-text search capabilities. Documents were indexed with fields such as case name, date, jurisdiction, and key topics.
- BM25 Algorithm: Implemented to rank documents based on relevance to the user’s query. Elasticsearch's native support for BM25 was leveraged for efficient retrieval.
4. Generative Model:
- Model Selection: GPT-4, known for its powerful language understanding and generation capabilities, was selected. It was initially pre-trained on a diverse dataset.
- Fine-tuning: The model was fine-tuned on legal-specific datasets to enhance its understanding of legal language and concepts. This involved formatting the data into question-answer pairs and dialogue formats.
- Frameworks: Hugging Face's Transformers library was used for model fine-tuning. PyTorch provided the backend for training and model adjustments.
5. RAG Integration:
- Combining Retrieval and Generation: The RAG approach involves using the retrieval system to fetch relevant documents, which are then provided as context to the generative model. This integration was crucial for improving response accuracy.
- Pipeline Construction: A pipeline was constructed where user queries were first processed by Elasticsearch to retrieve relevant documents. These documents were then input into the generative model to generate precise responses.
6. User Interaction and Interface:
- Web Development: A web application was developed using React for the frontend, ensuring a user-friendly and intuitive interface. The backend was built with FastAPI to handle API requests efficiently.
- Chatbot Integration: For conversational interactions, a chatbot interface was created using Node.js and integrated with platforms like Slack and Microsoft Teams.
7. Continuous Learning and Feedback:
- Feedback Mechanism: A feedback loop was implemented, allowing users to rate the accuracy and relevance of responses. This feedback was used to further fine-tune the model and improve the retrieval system.
- Active Learning: Periodic updates and retraining were conducted based on user feedback and new legal documents, ensuring Sir Frank stays up-to-date with legal standards and practices.
8. Legal and Ethical Considerations:
- Review Mechanism: A review system was established where legal professionals could validate and approve generated content, ensuring high standards of accuracy and reliability.
- Security Measures: Robust security protocols were implemented to protect user data, including encryption, secure authentication, and compliance with legal data protection regulations.
Technologies Used:
- NLP Libraries: SpaCy, NLTK for text processing; Hugging Face Transformers for model fine-tuning.
- Search and Indexing: Elasticsearch for indexing and search; Apache Lucene for additional search capabilities.
- Machine Learning Frameworks: PyTorch for training the generative model.
- Web Development: React for frontend; FastAPI for backend; Node.js for chatbot integration.
- Cloud Deployment: AWS for scalable and reliable cloud infrastructure, including EC2 for hosting, S3 for storage, and Lambda for serverless functions.
Notable Hacks and Techniques:
- Contextual Enhancements: To improve the accuracy of generated responses, a custom preprocessing step was added to enhance the context provided to the generative model, including summarizing long documents and extracting key points.
- Hybrid Search Techniques: In addition to BM25, vector-based search techniques using BERT embeddings were explored to improve the retrieval quality, especially for nuanced legal queries.
- Real-time Updates: A real-time data ingestion pipeline was set up to continuously update the legal document database, ensuring Sir Frank always has the latest legal information.
Sir Frank represents a sophisticated blend of advanced AI technologies, legal expertise, and user-centric design, making it a powerful tool for legal professionals seeking to streamline their workflow and enhance their productivity.

